Unlocking the Secrets of Cryptography: A Beginner’s Guide to Breaking Ciphers — Part 1
Historical Background
Cryptography has a long and fascinating history, dating back to ancient civilizations. The use of codes and ciphers allowed people to send messages that could not be understood by anyone who intercepted them.
One of the earliest known examples of cryptography comes from ancient Egypt, where hieroglyphs were often written in a code that only priests and scribes could understand. In ancient Greece, the famous Scytale was used as a cryptographic tool by Spartan military leaders to send secret messages during wartime.
During the Middle Ages, European monasteries were centers of learning and cryptography. Monks used simple ciphers and codes to protect their books and manuscripts from theft or unauthorized access. However, cryptography became much more sophisticated during the Renaissance, as new mathematical techniques were developed.
In the 20th century, the use of cryptography became increasingly important for government and military communication. During World War II, both the Allies and the Axis powers used sophisticated codes and ciphers to communicate securely. The most famous of these was the German Enigma machine, which was used to encrypt military messages and was famously broken by Alan Turing and his team at Bletchley Park.
In the modern era, cryptography has become an essential tool for protecting digital information, such as online transactions and confidential communications. Cryptography techniques are used in a wide variety of applications, from secure email to banking and e-commerce, and the field continues to evolve as new threats emerge and new encryption methods are developed.
Fundamental Definitions
Steganography: Originates from the Greek words “steganos” meaning “covered” and “graphein” meaning “to write”, is the practice of concealing the existence of a message as a means of achieving covert communication.
Cryptography: The term was coined from the Greek word “kryptos” meaning “hidden”. Its main objective is not to conceal the presence of a message, but rather to conceal its content through encryption.
Cryptanalysis: Refers to the process of deciphering ciphertext to plaintext without having complete knowledge of the encryption method used.
Cryptology: Cryptography + Cryptanalysis
Cryptosystem: A set of algorithms and protocols that are used to perform encryption and decryption of data, ensuring that the information remains secure and confidential during transmission and storage.
Example of a Basic Cipher: Shift Cipher
After explaining historical background and presenting fundamental definitions, let’s give some examples from classical era of cryptography. My first example will be Shift Cipher. A shift cipher is a simple form of encryption in which each letter in a message is replaced by another letter that is a fixed number of positions down the alphabet. For example, if the shift value is 3, then the letter ‘A’ would be replaced by the letter ‘D’, ‘B’ would become ‘E’, ‘C’ would become ‘F’, and so on. The shift value is also known as the key, and if it is kept secret, the message is considered encrypted. The shift cipher is one of the earliest and simplest methods of encryption and can be easily broken with a brute-force attack if the shift value is known. This method is named after Julius Caesar, who used it in his private correspondence.
Shift cipher is a substitution cipher, in particular it is a mono-alphabetic substitution cipher since a character is replaced with only other character. Our key space for shift cipher is 26! in English due to first letter can be replaced with 26 candidate characters, second one 25, so on so forth. Nowadays, it is easy to break such a cipher, but Caesar used it before the computer era for a long time. Here is my code to apply encrypt, decrypt and exhaustive search for a Shift Cipher:
Such ciphers are vulnerable to frequency attacks and I will explain it later with an example.
Can we improve this cipher? What if we encode a character with different characters regarding to a certain rule? Vigenère Cipher is a good example for it. The Vigenère Cipher is a poly-alphabetic substitution cipher that was invented by Blaise de Vigenère in the 16th century. It is a method of encrypting alphabetic text by using a series of interwoven Caesar ciphers, based on the letters of a keyword.
The Vigenère cipher works by using a keyword or key phrase that is repeated over and over again to generate a series of Caesar ciphers. Each letter of the keyword corresponds to a Caesar shift value, and the plaintext message is shifted by the corresponding shift value for each letter of the keyword. The result is a ciphertext message that is much more difficult to break than a simple Caesar cipher.
Cryptanalysis Time!
Another example for a poly-alphabetic cipher is Porta Cipher. Giovanni Battista Della Porta invented the Porta Cipher, a poly-alphabetic substitution cipher that utilizes 13 alphabets, in contrast to the Vigenere Cipher, which uses 26 alphabets. Due to its reciprocal nature, the cipher alphabets used in Porta Cipher enable the encryption and decryption processes to be the same.
The Porta Cipher employs the following tableau to encrypt a plaintext:

To use the Porta Cipher to a encrypt text, we should follow these steps:
- Choose a keyword
- Repeat the keyword above the plaintext message
- Find the corresponding value for each letter of the keyword and the plain text letter in the tableau
- Use these values to generate the ciphertext
Below is an example of encrypting a text using secret as the keyword:

Since we use a tableau of 13 rows, key space of Porta Cipher is 13^key_length.
Here is the encrypted text I used for this analysis:
In order to analyze the complete process, I have implemented a statistics collector class that can be used in future processes. The code for this class is shown below:
First of all, given plain text was long enough and we can understand it from its frequency analysis since it is too close to the original English letter frequencies. Letter probabilities sorted by descending in the English language are as follows (it is different at different resources):
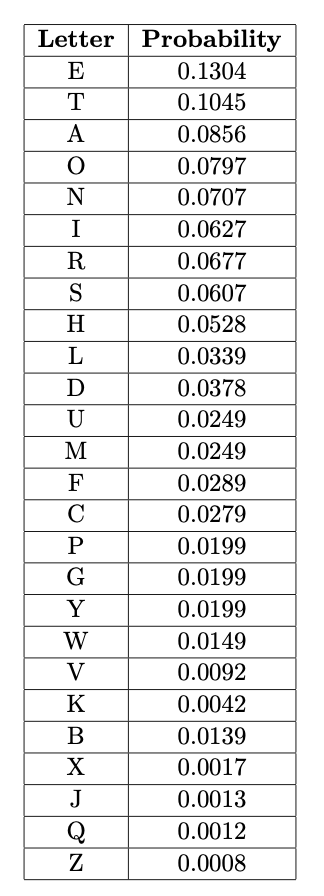
When we run a frequency analysis on the plaintext, we notice that:
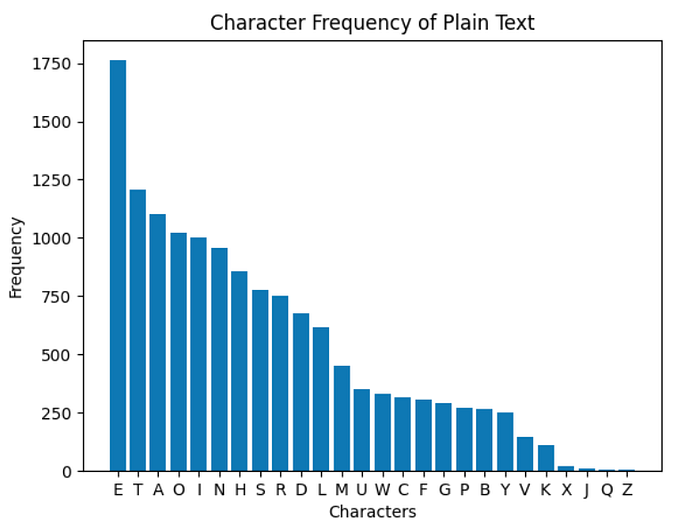
Plaintext has 13874 characters, 26 unique characters, and character distribution is too close to the original English letter probabilities. I used only ciphertext to find the key of the Porta Cipher, and as an initial step, I applied a frequency analysis on the ciphertext. Here is the output:
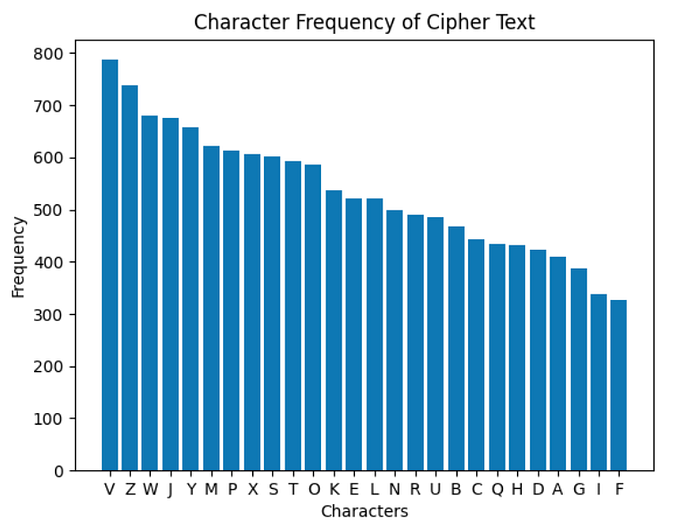
Ciphertext has 13874 characters and 26 unique characters like plain text. However, as shown, letter frequencies are near evenly distributed. So, this information helps us to understand this ciphertext not generated by a mono-alphabetic substitution cipher. As mentioned, Porta Cipher is a poly-alphabetic substitution cipher that correlates with that finding.
I tried to find the key length to break the Porta Cipher. I used the Index of Coincidence (IoC) method for that purpose (another alternative is using Kasiski Test). The Index of Coincidence (IoC) is a statistical measure of how similar a frequency distribution is to a uniform distribution.
The IoC is calculated simply by taking the sum of the frequencies of each letter in the ciphertext squared, divided by the total number of letters in the ciphertext:
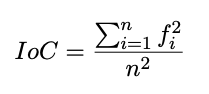
where fi is the frequency of the i-th letter in the ciphertext, and n is the total number of letters in the ciphertext.
Using probabilities, we can calculate that English letters have an approximate IoC value of 0.065. On the other hand, a random text will have a value IoC value of 0.038.
The length of the key is crucial in a poly-alphabetic substitution cipher. In such ciphers, a letter can be encrypted with a different character, but after the length of the key, the same character will be encrypted to the same character with a period equal to the length of the key.
To determine the key length, I began with a random key length and created substring clusters of that length. I filled the clusters with elements that have a gap of the key length between them.
Creating substrings according to the key length will not directly solve our problem. However, it will have characteristics of a mono-alphabetic substitution cipher and should have a similar IoC value to English letters. So, I divided ciphertext into different substrings (buckets) and compared their IoC concerning being close to 0.065. Here is the complete class I created to calculate IoC:
Below is the output of IoC values corresponding random key lengths:
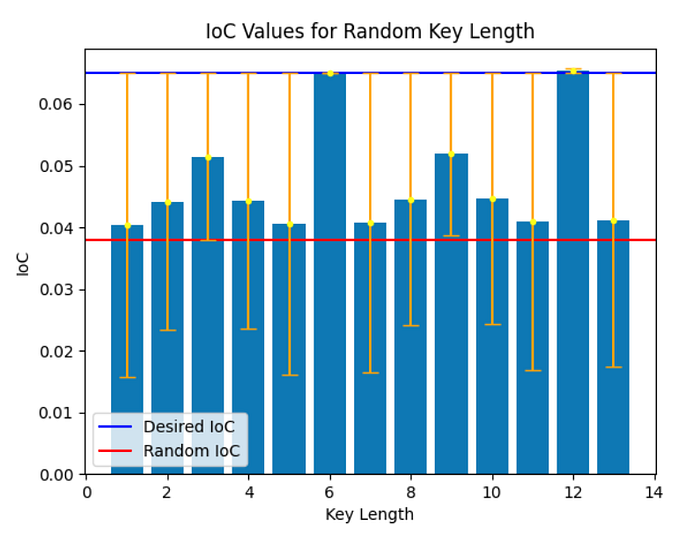
It reveals that the key lengths of 6 and 12 are in close proximity to the desired IoC values.
If the key length is 6, we can consider its multiples as possible key candidates since a 12-length key can be generated by repeating a 6-length key twice. Alternatively, we could test 12 since it may be the original key length. After analyzing these options, I initially accepted 6 as the key length and proceeded with it.
As the next step, I created substrings with a key length of 6. Below figure demonstrates my approach for the first 7 letters of the given ciphertext:
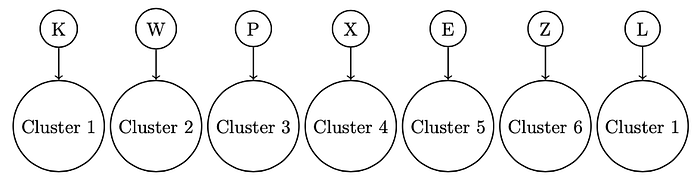
For each cluster of letters, I tried 13 transformations defined in the Porta tableau. However, the result of performing that transformations will not be meaningful since we have a scattered version of the candidate plaintext. One solution to understand whether we found a potential solution at one of the transformations is to measure the cluster statistics with English letter statistics. For that purpose, I applied the Chi-squared Statistic. The Chi-squared Statistic quantifies the dissimilarity between two categorical probability distributions. If the two distributions are the same, the Chi-squared Statistic will be 0, whereas if the distributions are substantially different, the statistic will be larger.
The formula for the Chi-squared Statistic is:
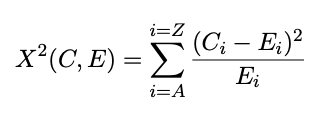
where C_i is the count of letter i, and E_i is the expected count of letter i. To calculate the expected count of a given letter, I multiplied the total number of letters with letter probability defined at English letter probabilities table.
Below is the code I implemented to calculate the Chi-squared Statistics of each cluster:
The results of the Chi-squared Statistics for applying each key element transformation to each cluster are shown below:

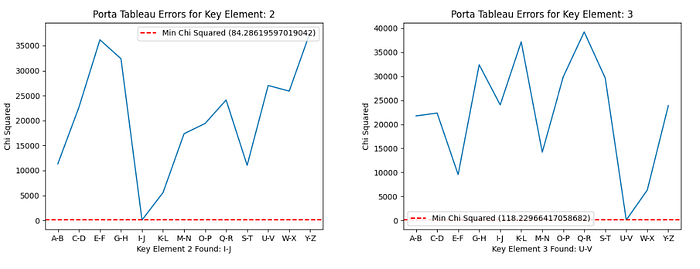
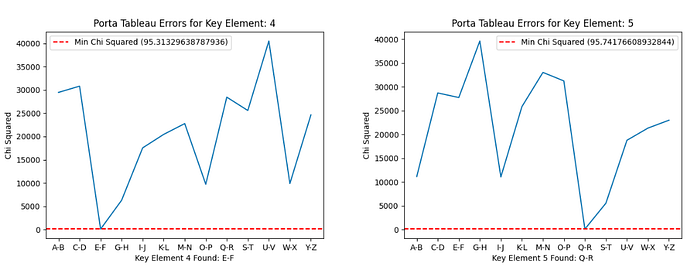
So, the candidate key is all of the combinations of these letters:
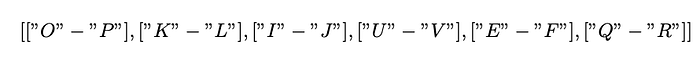
One of the meaningful words from that combination is OLIVER, and I accepted it as the potential key. I created the below class for Porta cipher operations:
When I used that key, Porta Cipher broken, and I got the exact match with plaintext. As a final remark, if I couldn’t get a match, I had to back-propagate from candidate key elements and different key lengths.
Overall, one of the found keys is:
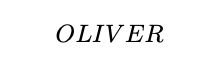
As a final remark, independently working on elements of key length let us consider 13 ∗ key length candidates instead of trying 13^key length possibilities.
What is Next?
In the next post, I will cover Shannon’s theory and product cryptosystems. For this purpose, I will modify our Porta Cipher example and attempt to break the modified version.
Don’t forget to follow me on Twitter: https://twitter.com/kamaci_furkan
Stay tuned!
References
[1] David Kahn. The Codebreakers: The Comprehensive History of Secret Communication from Ancient Times to the Internet. Scribner, 1996, p. 139. isbn: 9780684831305.
[2] Keith M. Martin. Everyday Cryptography. Oxford University Press, 2012, p. 142. isbn: 9780191625886.
[3] Berna Örs Yalçın. Lecture notes in Cryptography. Apr. 2023.
[4] William F Friedman. The index of coincidence and its applications in cryptography. Riverbank Laboratories. Department of Ciphers. Publ. OCLC, 1922.
[5] Practical Cryptography. Chi-squared Statistic. url: http://practicalcryptography.com/cryptanalysis/ text-characterisation/chi-squared-statistic/. (Accessed: 03.04.2023).
[6] Douglas R. Stinson and Maura B. Paterson. Cryptography: Theory and Practice. 4th. Boca Raton, FL: CRC Press, 2019, pp. 75–78. isbn: 9781138197015.
[7] Vittorio et. al Maniezzo. Matheuristics, Algorithms and Implementations. Springer International Pub- lishing, 2021.
[8] Bill Waggener. Pulse Code Modulation Techniques. Springer, 1995, p. 206. isbn: 9780442014360.
